
Volcano es un proyecto de la Cloud Native Computing Foundation (CNCF) que se utiliza principalmente como sistema batch en el ámbito de la IA y para aplicaciones de Big Data cuando el entorno está construido sobre Kubernetes.
El proyecto Volcano de la CNCF es un sistema batch construido sobre Kubernetes. El enfoque de las cargas de trabajo es principalmente cargas de trabajo del campo de la IA (aprendizaje automático/aprendizaje profundo) y otras aplicaciones de Big Data que causan una alta carga computacional y deben ser programadas de manera óptima en el clúster Kubernetes.
Frameworks como "Tensorflow", "Spark", "Pytorch", "MPI", "Flink", "Argo", "Mindspore" y "PaddlePaddle" que requieren cargas de trabajo con gran carga de trabajo funcionan bien con Volcano. Volcano soporta la integración con varios marcos de computación, por ejemplo "Kubeflow" y "Kubegene".
Volcano extiende Kubernetes con varias funciones. Estas incluyen principalmente extensiones de programación, extensiones de gestión de trabajos y aceleradores como GPU y FPGA.
Programación agrupada para contenedores
Volcano es uno de los proyectos surgidos de "Kube Batch". El proyecto se creó originalmente para agrupar mejor los contenedores y programar los recursos.
Especialmente para las soluciones de IA y Big Data, Volcano en los clústeres Kubernetes es un componente importante para una mejor utilización de los recursos. Con Volcano, es posible acelerar significativamente las cargas de trabajo de IA en los clústeres de Kubernetes.
Originalmente fue aceptado por el CNCF en 2015 como un proyecto de "sistema nativo de Kubernetes para cargas de trabajo de alto rendimiento", y obtuvo la designación de Volcano en 2019. El código fuente y los problemas del proyecto también se pueden encontrar en Github.
Adición para el programador de Kubernetes
El programador de Kubernetes programa los contenedores de uno en uno. Esto es útil para muchos escenarios, pero raramente para cargas de trabajo con tareas de cálculo intensivo. Especialmente cuando se entrenan entornos de IA y también en los análisis de Big Data, grupos enteros de contenedores suelen desempeñar un papel importante.
Si una aplicación necesita varios contenedores para su ejecución, puede ocurrir con el planificador estándar de Kubernetes, provocado por la programación única, que los contenedores individuales del grupo no puedan arrancar porque no hay suficientes recursos disponibles. Como resultado, estas cargas de trabajo se ejecutan con menos eficacia, o no se ejecutan en absoluto.
Pero al mismo tiempo, los contenedores del grupo ya iniciados provocan recursos que no sirven para nada, porque falta un componente esencial del grupo. Este es el enfoque de Volcano. La solución combina todo el grupo de contenedores interdependientes y programa sus recursos conjuntamente.
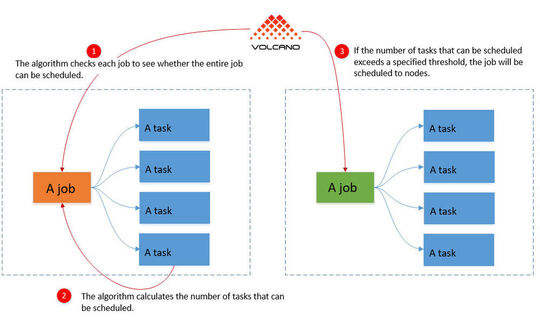
Si todos los contenedores del grupo no pueden iniciarse, Volcano impide que todos los contenedores del grupo se inicien. Esto reduce significativamente la carga en el clúster de Kubernetes, ya que en este caso al menos hay recursos disponibles para otros contenedores y grupos de contenedores. Si varios de estos grupos se ejecutan en un clúster, el uso de Volcano tiene mucho sentido.
Asignación automática de recursos para contenedores
Volcano tiene una visión completa de los contenedores individuales en Kubernetes a través de sus funciones internas, pero también de los grupos de contenedores que proporcionan conjuntamente una carga de trabajo. Además de agrupar y compartir recursos entre contenedores, el software también puede identificar qué nodos son los más adecuados para aprovisionar los contenedores individuales de un grupo.
La CPU, la memoria, la GPU y otros recursos también pueden programarse específicamente y ponerse a disposición de los contenedores de un grupo. Volcano conoce los recursos libres y la carga máxima de todos los nodos. Basándose en esta información, Volcano selecciona el nodo más adecuado para cada contenedor.
Volcano también ofrece la posibilidad de trabajar con prioridades. Funciones como Domain Resource Fairness (DRF) y Binpack también están integradas en Volcano y pueden tenerse en cuenta en la planificación de recursos. Si varios grupos compiten entre sí o no deben usarse juntos en un nodo, esto se puede tener en cuenta con Volcano.
Cómo funciona Volcano
El DRF (Domain Resource Fairness) puede priorizar los trabajos, incluso en YARN y Mesos. Por ejemplo, el DRF también puede dar prioridad a los trabajos que requieren menos recursos. Esto hace que el clúster pueda ejecutar más trabajos y que las tareas pequeñas no se vean bloqueadas por las aplicaciones grandes. En Volcano, DRF define un trabajo como la totalidad de todos los contenedores necesarios para una tarea definida.
El algoritmo binpack intenta utilizar todos los nodos del clúster en la medida de lo posible. Las configuraciones pueden hacerse de manera que los nodos se ocupen por completo antes de que Volcano ocupe otros nodos. Binpack planifica la utilización de todos los nodos del clúster y luego programa los trabajos individuales de acuerdo con estas especificaciones.
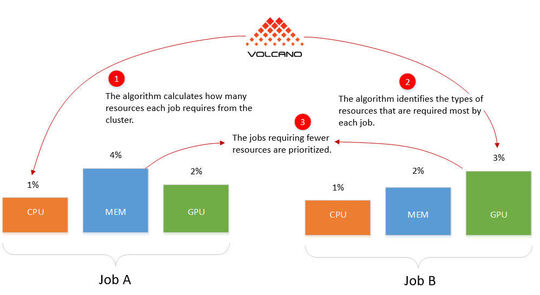
El algoritmo de colas puede controlar toda la asignación de recursos de un clúster. Esta técnica también se utiliza en YARN. Si varios grupos de contenedores comparten un pool de recursos en un cluster, Volcano puede controlar qué grupo necesita más recursos.
De esta manera, Volcano también reconoce en tal escenario qué grupo probablemente utiliza menos recursos y puede ejecutar este grupo primero. Una vez completadas sus tareas, Volcano puede programar el grupo con mayor carga de recursos. Volcano puede ponderar de forma diferente sus diferentes complementos de algoritmos de programación.
Ergo: Si se utilizan cargas de trabajo en un clúster Kubernetes que se basan en varios contenedores y pods y tienen un alto consumo de recursos, Volcano puede aportar importantes ventajas. Su uso es especialmente útil cuando se trabaja con cargas de trabajo de IA, por ejemplo para el aprendizaje automático y el aprendizaje profundo. Pero otras cargas de trabajo que consumen muchos recursos en el área de Big Data para el renderizado y los cálculos exhaustivos también se benefician de Volcano.
Por último, Volcano también aporta algunas ventajas para las demás cargas de trabajo del clúster, ya que la programación de recursos mucho mejor significa que las demás cargas de trabajo también pueden utilizar más recursos, o tienen prioridad en el arranque porque necesitan menos recursos y, por tanto, terminan su trabajo más rápidamente.
* El autor Thomas Joos es consultor informático y escribe libros y artículos técnicos. En DataCenter-Insider llena su propio blog de consejos y trucos para administradores. "Blog de administración de Tom".